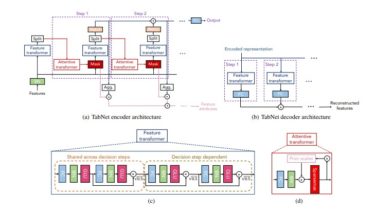
An implementation of Performer, a linear attention-based transformer in Pytorch
Performer – Pytorch An implementation of Performer, a linear attention-based transformer variant with a Fast Attention Via positive Orthogonal Random features approach (FAVOR+). Install $ pip install performer-pytorch Then you must run the following, if you plan on training an autoregressive model $ pip install -r requirements.txt Usage Performer Language Model import torch from performer_pytorch import PerformerLM model = PerformerLM( num_tokens = 20000, max_seq_len = 2048, # max sequence length dim = 512, # dimension depth = 12, # layers […]
Read more