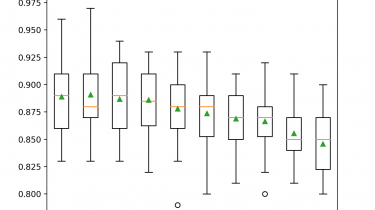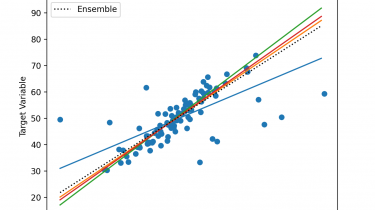
Develop an Intuition for How Ensemble Learning Works
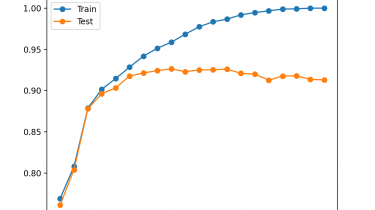
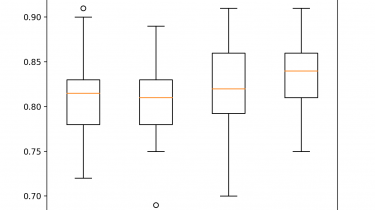
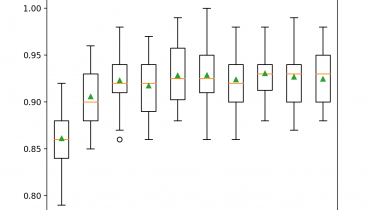
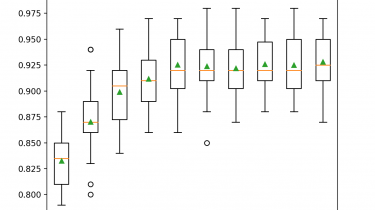
Ensembles are a machine learning method that combine the predictions from multiple models in an effort to achieve better predictive performance. There are many different types of ensembles, although all approaches have two key properties: they require that the contributing models are different so that they make different errors and they combine the predictions in an attempt to harness what each different model does well. Nevertheless, it is not clear how ensembles manage to achieve this, especially in the context […]
Read more