What’s going on with the Open LLM Leaderboard?
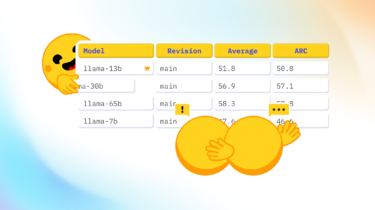
Recently an interesting discussion arose on Twitter following the release of Falcon 🦅 and its addition to the Open LLM Leaderboard, a public leaderboard comparing open access large language models.
The discussion centered around one of the four evaluations displayed on the leaderboard: a benchmark for measuring Massive Multitask Language Understanding (shortname: MMLU).
The community was surprised that MMLU evaluation numbers of the current top model on the leaderboard, the LLaMA model 🦙, were significantly lower than the numbers in the published LLaMa paper.
So we decided to dive in a