Promise of Deep Learning for Natural Language Processing
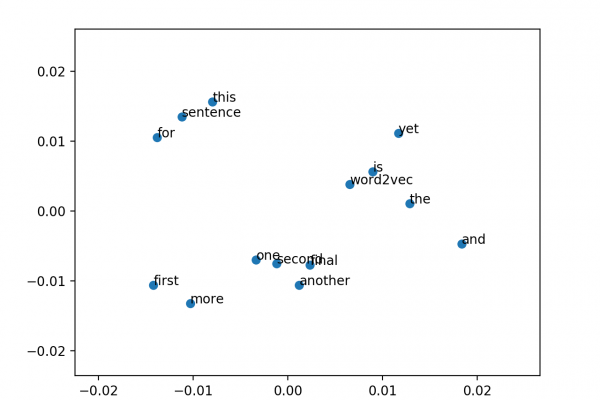
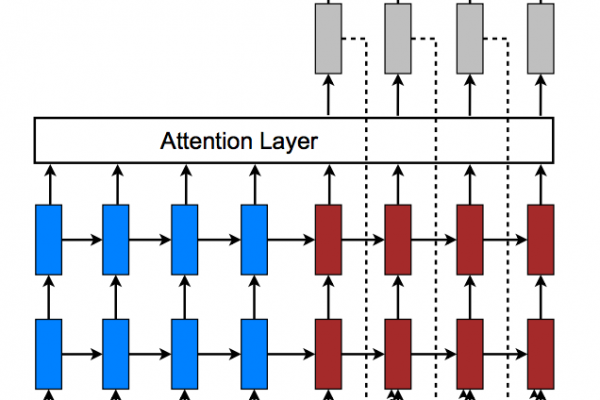
Last Updated on August 7, 2019 The promise of deep learning in the field of natural language processing is the better performance by models that may require more data but less linguistic expertise to train and operate. There is a lot of hype and large claims around deep learning methods, but beyond the hype, deep learning methods are achieving state-of-the-art results on challenging problems. Notably in natural language processing. In this post, you will discover the specific promises that deep learning […]
Read more