Case Study: Predicting the Onset of Diabetes Within Five Years (part 3 of 3)
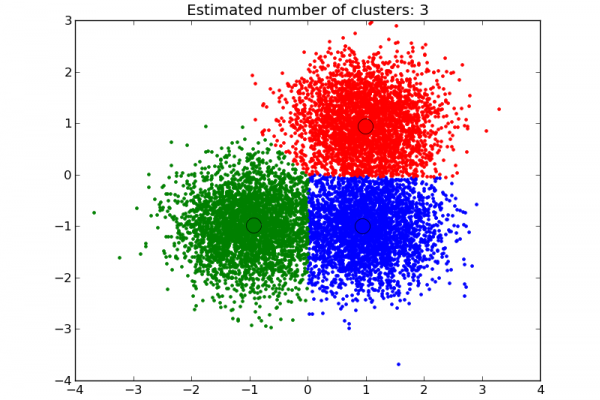
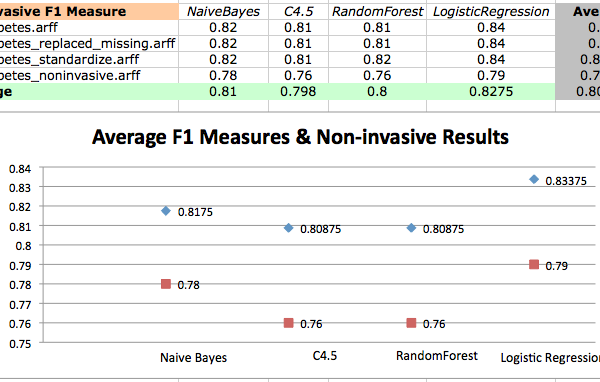
Last Updated on August 22, 2019 This is a guest post by Igor Shvartser, a clever young student I have been coaching. This post is part 3 in a 3 part series on modeling the famous Pima Indians Diabetes dataset that will investigate improvements to the classification accuracy and present final results (update: download from here). In Part 1 we defined the problem and looked at the dataset, describing observations from the patterns we noticed in the data. In Part 2 we […]
Read more