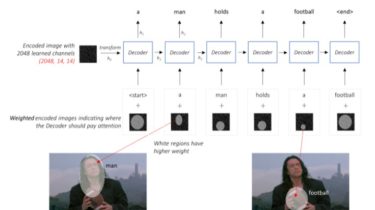
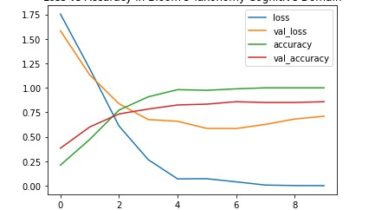
Partially-observed visual reinforcement learning domain
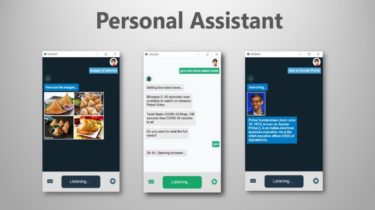
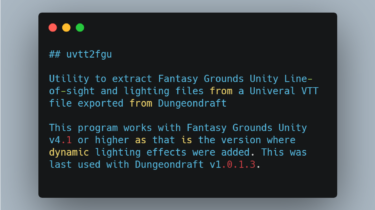
CowHerd CowHerd is a partially-observed reinforcement learning environment, where the player walks around an area and is rewarded for milking cows. The cows try to escape and the player can place fences to help capture them. The implementation of CowHerd is based on the Crafter environment. Play Yourself You can play the game yourself with an interactive window and keyboard input.The mapping from keys to actions, health level, and inventory state are printedto the terminal. # Install with GUI pip3 […]
Read more