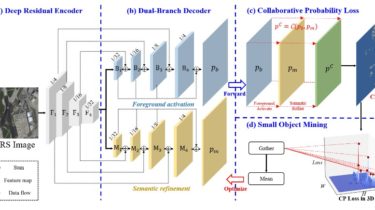
A Python tool to generate a static HTML file that represents the internal structure of a PDF file
A Python tool to generate a static HTML file that represents the internal structure of a PDF file At some point the low-level functions developed for this CLI will be exposed as an API for programmatic use. WORK IN PROGRESS! CLI Features The generated HTML looks like the raw PDF file with the following additions: Pretty-print dictionary object Extract an object contained in an object stream and insert it in the flow like a regular object Decompress stream and display […]
Read more