Back to The Future: Evaluating AI Agents on Predicting Future Events
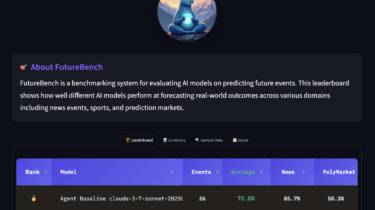
Most current AI benchmarks focus on answering questions about the past, either by testing models on existing knowledge (in a static manner, such as HLE or GPQA, or augmented, like BrowseComp or GAIA) or previously solved problems (like PaperBench, DABStep, or most coding evaluations). However, we believe that more valuable AI, and ultimately AGI, will be distinguished by its ability to use this past to forecast interesting aspects of the future, rather than merely reciting old facts. Forecasting future events […]
Read more