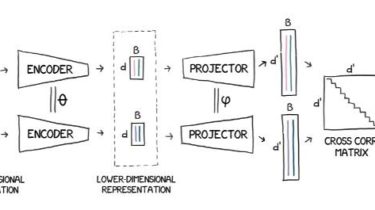
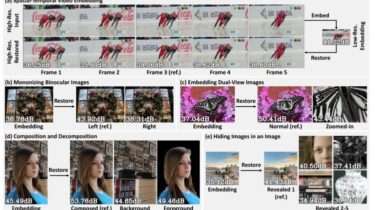
The NLP Cypher | 10.17.21
David is killing it! Welcome back NLP peeps! Do you miss the old days? The old internet days of modem calling, static websites, you know… a time of innocence where developers were innovating the backbone of the internet at hyper speeds? Well, we are very much going thru that right now via the Web 3.0 revolution. Cryptocurrencies usually get all of the attention but there is something else at play and it involves the entire web. You see, the current […]
Read more