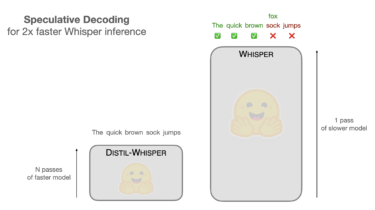
Speculative Decoding for 2x Faster Whisper Inference
Open AI’s Whisper is a general purpose speech transcription model that achieves state-of-the-art results across a range of different benchmarks and audio conditions. The latest large-v3 model tops the OpenASR Leaderboard, ranking as the best open-source speech transcription model for English. The model also demonstrates strong multilingual performance, achieving less
Read more






