

SDXL in 4 steps with Latent Consistency LoRAs
Latent Consistency Models (LCM) are a way to decrease the number of steps required to generate an image with Stable Diffusion (or SDXL) by distilling the original model into another version that requires fewer steps (4 to 8 instead of the original 25 to 50). Distillation is a type of training procedure that attempts to replicate the outputs from a source model using a new one. The distilled model may be designed to be smaller (that’s the case of DistilBERT […]
Read more
Open LLM Leaderboard: DROP deep dive
Recently, three new benchmarks were added to the Open LLM Leaderboard: Winogrande, GSM8k and DROP, using the original implementations reproduced in the EleutherAI Harness. A cursory look at the scores for DROP revealed something strange was going on, with the overwhelming majority of models scoring less than 10 out of 100 on their f1-score! We did a deep dive to understand what was going on, come with us to see what we found out! Initial
Read more
Goodbye cold boot – how we made LoRA Inference 300% faster
tl;dr: We swap the Stable Diffusion LoRA adapters per user request, while keeping the base model warm allowing fast LoRA inference across multiple users. You can experience this by browsing our LoRA catalogue and playing with the inference widget. In this blog we will go in detail over how we achieved that. We’ve
Read more
Optimum-NVIDIA on Hugging Face enables blazingly fast LLM inference in just 1 line of code
Large Language Models (LLMs) have revolutionized natural language processing and are increasingly deployed to solve complex problems at scale. Achieving optimal performance with these models is notoriously challenging due to their unique and intense computational demands. Optimized performance of
Read more
AMD + 🤗: Large Language Models Out-of-the-Box Acceleration with AMD GPU
Earlier this year, AMD and Hugging Face announced a partnership to accelerate AI models during the AMD’s AI Day event. We have been hard at work to bring this vision to reality, and make it easy for the Hugging Face community to run the latest AI models on AMD hardware with the best possible performance. AMD is powering some of the most powerful supercomputers in the World, including the fastest European one, LUMI, which operates over 10,000 MI250X AMD GPUs. […]
Read more
SetFitABSA: Few-Shot Aspect Based Sentiment Analysis using SetFit
SetFitABSA is an efficient technique to detect the sentiment towards specific aspects within the text. Aspect-Based Sentiment Analysis (ABSA) is the task of detecting the sentiment towards specific aspects within the text. For example, in the sentence, “This phone has a great screen, but its battery is too small”, the aspect terms are “screen” and “battery” and the sentiment polarities towards them are Positive and Negative, respectively. ABSA is widely used by organizations for extracting valuable insights by analyzing customer […]
Read more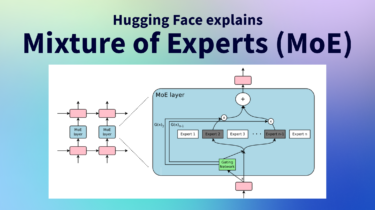
Mixture of Experts Explained
There is a second iteration (Feb 2026) of the blog post where we cover how the transformers library has built around MoEs to make them “first class citizens” of the library and the Hub. Here is the link to the post: Mixture of Experts (MoEs) in Transformers With the release of Mixtral 8x7B (announcement, model card), a class of transformer has become the hottest topic in the open AI community: Mixture of Experts, or MoEs for short. In this blog […]
Read more
Welcome Mixtral – a SOTA Mixture of Experts on Hugging Face
Mixtral 8x7b is an exciting large language model released by Mistral today, which sets a new state-of-the-art for open-access models and outperforms GPT-3.5 across many benchmarks. We’re excited to support the launch with a comprehensive integration of Mixtral in the Hugging Face ecosystem 🔥! Among the features and integrations being released today, we have: Table of Contents What is
Read more
2023, year of open LLMs
2023 has seen a surge of public interest in Large Language Models (LLMs), and now that most people have an idea of what they are and can do, the public debates around open versus closed source have reached a wide audience as well. At Hugging Face, we follow open models with great interest, as they allow research to be reproducible, empower the
Read more