NLP-Knowledge Graph
Explore different libraries and create production ready code
Read moreDeep Learning, NLP, NMT, AI, ML

Explore different libraries and create production ready code
Read more
How to effectively and efficiently build AI products using Large Language Models
Read more
If you’ve been hanging out in the Python community for a while, you may remember discussions about Python 2 vs Python 3, or you may have seen versions like Python 3.10 and Python 3.11 released with some fanfare. You may have noticed that Python versions have three numbers—for example, 3.10.8. In this tutorial, you’ll focus on Python bugfix versions and the importance of that third number. For any developer, designing a versioning scheme and interpreting the corresponding version numbers is […]
Read more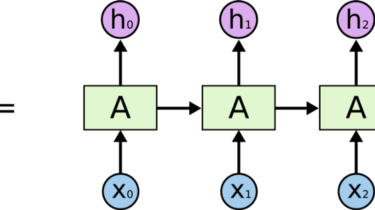
These years, there has been widely speared applications employing Natural Language Processing (NLP) technologies, including question answering system, Machine reading comprehension, summarization, dialogue, autocompletion, machine translation, etc.From 2013 to 2014, the applications of various neural network models on NLP have gradually increased, among which the most widely used are: convolutional neural networks (CNN), recurrent neural networks (RNN), and structural recurrent neural networks (SRN). Since the text is ordered, the sequential structure of RNN (recurrent neural network) makes it the […]
Read more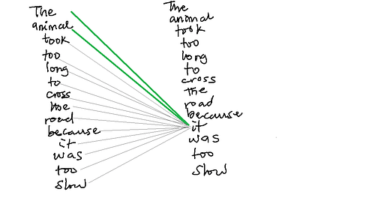
The continuous innovation around contextual understanding of sentences has expanded significant bounds in NLP. The general idea of Transformer architecture is based on self-attention proposed in Attention is All You Need paper 2017.Self-attention is learning to weigh the relationship between each item/word to
Read moreText summarization is a text generation task, which generates a concise and precise summary of input texts. There are two kinds of summarization tasks in Natural Language Processing, one is the extractive approach, which is to identify the most important sentences or phrases in the original text and combine them to make a summary. The more advanced approach is the abstractive approach, which generates new phrases and sentences to represent the information from the input text.
Read moreOn your Python journey, you’ve probably learned about functions and loops. To fully understand functions and loops in Python, you need to be familiar with the issue of scope. By the end of this video course, you’ll know: What a scope is and why it’s important How Python applies the LEGB rule for scope resolution Scope can be one of the more difficult programming concepts to understand, so in this video course, you’ll get a gentle introduction to it. This […]
Read more
2022/10/28 I am still really struggling not to procrastinate. I will try my best and put in minimal work every day. I was initially going to make
Read more
Google Image (NLP)
Read more
Samia S. Azim1, Varun Aggrawal2, and Dharmendra Sarsawat3 1Department of Computer Science, Institute of Business Administration Karachi 2Elmore School of Electrical and Computer Engineering
Read more