Improving Prompt Consistency with Structured Generations
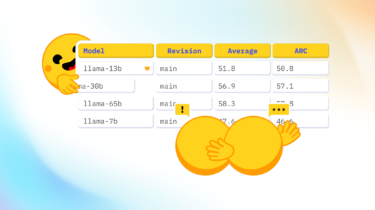
Recently, the Leaderboards and Evals research team at Hugging Face did small experiments, which highlighted how fickle evaluation can be. For a given task, results are extremely sensitive to minuscule changes in prompt format! However, this is not what we want: a model prompted with the same amount of information as input should output similar results.
We discussed this with our friends at Dottxt, who had an idea – what if there was a way to increase consistency across prompt formats?
So, let’s dig in!