
Category: Python
Python tutorials
LamdenLink Bridge Status Update
The team is very grateful for everyone’s continued patience. We’re diligently working out the details to re-enable the LamdenLink bridge while minimizing impacts to the community. We had a productive call yesterday with community developers to discuss options. The proposed idea (thank Benji) we’re currently evaluating is to write-off
Read more
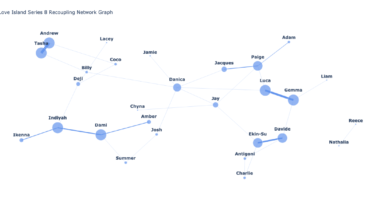
Love Island Recouplings: A Network Analysis
When I’m honest with myself my two main interests are crap reality TV and telling stories with data. That’s ordered by my own interest too. For a long time I found it almost impossible to blend these two seemingly unrelated passions, until I read a bit about Network Analysis.
Read more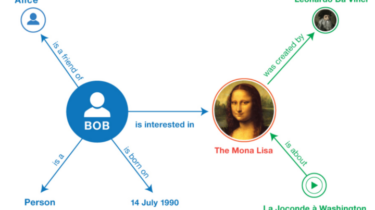
A brief summary of Knowledge Graphs
Knowledge representation and reasoning is one of the popular fields in artificial intelligence dedicated to offering methods that will make it possible to build complex systems by trying to incorporate how people represent information and solve problems. It can be said as the main technology for the Semantic Web.. The Semantic Web combine concepts from knowledge representation and reasoning with markup languages based on XML. Resource Description Framework (RDF) and The Web Ontology Language(OWL) provide methods for modeling knowledge-based objects […]
Read more
ChatterBot: Build a Chatbot With Python
Chatbots can provide real-time customer support and are therefore a valuable asset in many industries. When you understand the basics of the ChatterBot library, you can build and train a self-learning chatbot with just a few lines of Python code. You’ll get the basic chatbot up and running right away in step one, but the most interesting part is the learning phase, when you get to train your chatbot. The quality and preparation of your training data will make a […]
Read moreVideo: Accelerate Transformer Training with Optimum Graphcore
In this video, I show you how to accelerate Transformer training with Optimum Graphcore, an open-source library by Hugging Face that leverages the Graphcore AI processor. First, I walk you through the setup of a Graphcore-enabled notebook on Paperspace. Then, I run
Read more
Elasticsearch: Search optimization
7 ideas on how to use NLP to optimize your search engine with code Written by Daniel Popek and Paweł Mielniczuk.
Read more
All About Python Backends FastAPI vs Django vs Flask… ??? (2022)
This article compares the Python frameworks used by Intel, IBM, NASA, Pixar, Netflix, Facebook, JP Morgan Chase, Spotify, Nebula and other companies, despite criticism that it is a slow language.
Read more
Django Jet ile Nasıl Daha iyi Django Admin Sayfası Tasarlanır ?
Django Admin Sayfası bir database yönetim sayfasıdır. Model classlarımızda oluşturduğumuz objeler ORM ile db’ye aktarılır. Django’nun admin sayfası birçok kişiye göre sade kalmaktadır, gerçek bir admin dashboard’ına nasıl benzetebiliriz hangi kütüphaneleri kullanmalıyız bu yazımda bu konudan bahsedeceğim. Örnek Django Jet Uygulaması:
Read more