Syntactic Nuclei in Dependency Parsing – A Multilingual Exploration
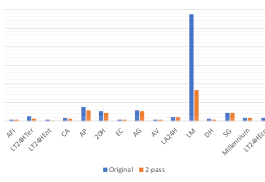
In the previous sections, we have shown how syntactic nuclei can be identified in the UD annotation and how transition-based parsers can be made sensitive to these structures in their internal representations through the use of nucleus composition. We now proceed to a set of experiments investigating the impact of nucleus composition on a diverse selection of languages. 5.1 Experimental Settings We use UUParser (de Lhoneux et al., 2017, Smith
Read more