One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective
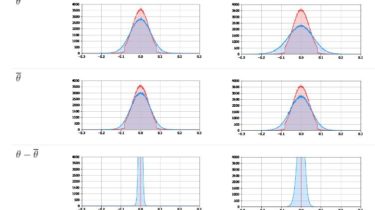
ArXiv (pdf) Official pytorch implementation of the paper: “One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective” NeurIPS 2021 Released on September 29, 2021 This paper proposes a novel deep hashing model with only a single learning objective which is a simplification from most state of the art papers generally use lots of losses and regularizer. Specifically, it maximizes the cosine similarity between the continuous codes and their corresponding binary orthogonal codes to ensure both […]
Read more