Basics of Natural Language Processing(NLP) for Absolute Beginners
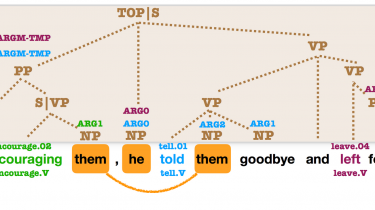
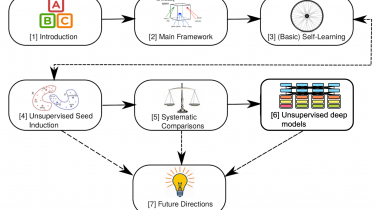
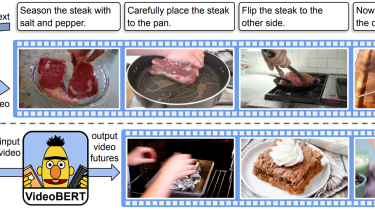
Introduction According to industry estimates, only 21% of the available data is present in a structured form. Data is being generated as we speak, as we tweet, as we send messages on WhatsApp and in various other activities. The majority of this data exists in the textual form, which is highly unstructured in nature. Despite having high dimension data, the information present in it is not directly accessible unless it is processed (read and understood) manually or analyzed by an […]
Read more