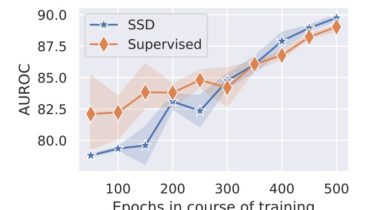
Regularizing Generative Adversarial Networks under Limited Data
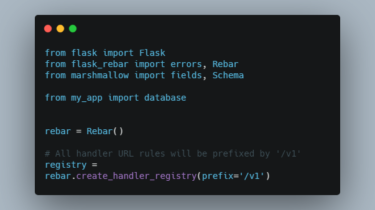
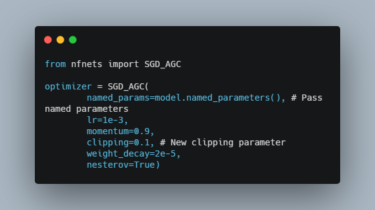
lecam-gan Regularizing Generative Adversarial Networks under Limited Data Implementation for our GAN regularization method. The proposed regularization 1) improves the performance of GANs under limited training data, and 2) complements the exisiting data augmentation approches. Please note that this is not an officially supported Google product. Paper Please cite our paper if you find the code or dataset useful for your research. Regularizing Generative Adversarial Networks under Limited Data Hung-Yu Tseng, Lu Jiang, Ce Liu, Ming-Hsuan Yang, Weilong Yang Computer […]
Read more