ITBench-AA: Frontier Models Score Below 50% on the First Benchmark for Agentic Enterprise IT Tasks — by Artificial Analysis and IBM
Artificial Analysis and IBM Software Innovation Lab are launching ITBench-AA, the first in a new series of benchmarks evaluating models on agentic enterprise IT tasks, starting with Site Reliability Engineering tasks where frontier models score below 50%
ITBench-AA’s SRE tasks benchmark model performance on Kubernetes incident response, where models and agents must diagnose live systems by reading logs, tracing dependencies, and identifying root-cause entities across complex infrastructure. The underlying ITBench dataset has been developed by IBM, leveraging deep expertise in enterprise IT operations.
Artificial Analysis has worked closely with IBM over the last 6 months to develop an implementation of the dataset for frontier AI evaluation, beginning with Site Reliability Engineering (SRE) and expanding to Financial Operations (FinOps) and Chief Information Security Officer (CISO) tasks over time.
ITBench-AA’s SRE tasks benchmark model performance on Kubernetes incident response, where models and agents must diagnose live systems by reading logs, tracing dependencies, and identifying root-cause entities across complex infrastructure. The underlying ITBench dataset has been developed by IBM, leveraging deep expertise in enterprise IT operations.
Artificial Analysis has worked closely with IBM over the last 6 months to develop an implementation of the dataset for frontier AI evaluation, beginning with Site Reliability Engineering (SRE) and expanding to Financial Operations (FinOps) and Chief Information Security Officer (CISO) tasks over time.

Key findings:
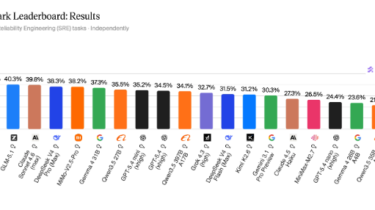
- Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%.
- All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite. For context, frontier models