Beyond Semantic Similarity: Introducing NVIDIA NeMo Retriever’s Generalizable Agentic Retrieval Pipeline
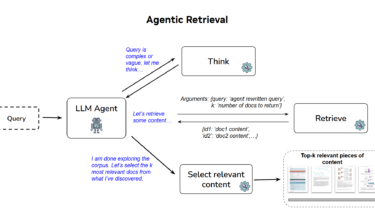
In the rapidly evolving landscape of AI retrieval, many solutions are highly specialized, engineered to perform exceptionally well on specific, narrow tasks. However, real-world enterprise applications rarely have the luxury of perfectly curated, single-domain data. They require systems that can seamlessly adapt to a wide variety of challenges—from parsing complex visual layouts to executing deep logical reasoning.
That is why we prioritized generalizability in our design. Rather than relying on dataset-specific heuristics, we built an agentic pipeline that dynamically adapts its search and reasoning strategy to the data at hand. This allows us to deliver state-of-the-art performance across vastly different benchmarks without requiring any underlying architectural changes.
Here is a look at how we built it.
The Motivation: Why Semantic Similarity Isn’t Enough
For years, dense retrieval