Very Large Language Models and How to Evaluate Them

Large language models can now be evaluated on zero-shot classification tasks with Evaluation on the Hub!
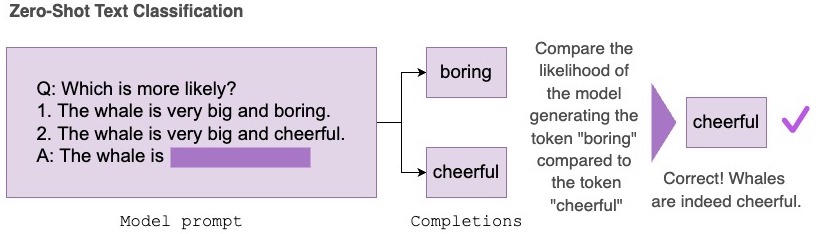
Zero-shot evaluation is a popular way for researchers to measure the performance of large language models, as they have been shown to learn capabilities during training without explicitly being shown labeled examples. The Inverse Scaling Prize is an example of a recent community effort to conduct large-scale zero-shot evaluation across model sizes and families to discover tasks on which larger models may perform worse than their smaller counterparts.