Fine-tuning LLMs to 1.58bit: extreme quantization made easy
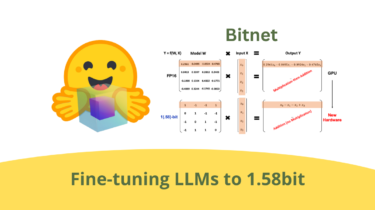
As Large Language Models (LLMs) grow in size and complexity, finding ways to reduce their computational and energy costs has become a critical challenge. One popular solution is quantization, where the precision of parameters is reduced from the standard 16-bit floating-point (FP16) or 32-bit floating-point (FP32) to lower-bit formats like 8-bit or 4-bit. While this approach significantly cuts down on memory usage and speeds up computation, it often comes at the expense of accuracy. Reducing the precision too much can cause models to lose crucial information, resulting in degraded performance.
BitNet is a special transformers architecture that