mlscraper: Scrape data from HTML pages automatically with Machine Learning
mlscraper
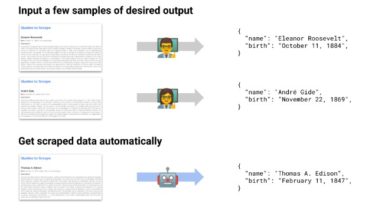
mlscraper allows you to extract structured data from HTML automatically with Machine Learning. You train it by providing a few examples of your desired output. It will then figure out the extraction rules for you automatically and afterwards you’ll be able to extract data from any new page you provide.
How it works
After you’ve defined the data you want to scrape, mlscraper will:
- find your samples inside the HTML DOM
- determine which rules/methods to apply for extraction
- extract the data for you and return it in a dictionary
import requests
from mlscraper import RuleBasedSingleItemScraper
from mlscraper.training import SingleItemPageSample
# the items found on the training page
targets = {
"https://test.com/article/1": {"title": "One great result!", "description": "Some description"},
"https://test.com/article/2": {"title": "Another great result!",