Gradient Descent With Momentum from Scratch
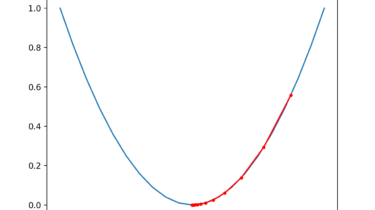
Gradient descent is an optimization algorithm that follows the negative gradient of an objective function in order to locate the minimum of the function. A problem with gradient descent is that it can bounce around the search space on optimization problems that have large amounts of curvature or noisy gradients, and it can get stuck in flat spots in the search space that have no gradient. Momentum is an extension to the gradient descent optimization algorithm that allows the search […]
Read more