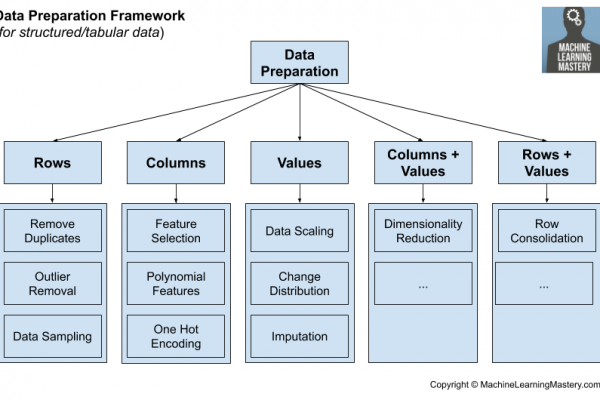
Framework for Data Preparation Techniques in Machine Learning
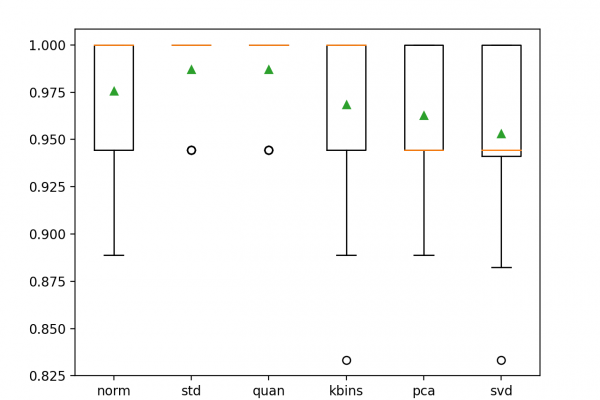
Last Updated on July 17, 2020 There are a vast number of different types of data preparation techniques that could be used on a predictive modeling project. In some cases, the distribution of the data or the requirements of a machine learning model may suggest the data preparation needed, although this is rarely the case given the complexity and high-dimensionality of the data, the ever-increasing parade of new machine learning algorithms and limited, although human, limitations of the practitioner. Instead, […]
Read more