Gentle Introduction to the Adam Optimization Algorithm for Deep Learning
Last Updated on August 20, 2020
The choice of optimization algorithm for your deep learning model can mean the difference between good results in minutes, hours, and days.
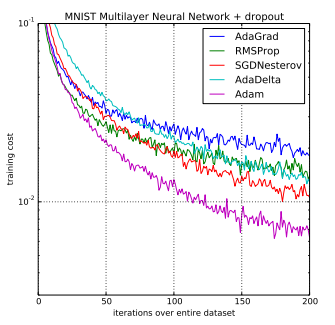
The Adam optimization algorithm is an extension to stochastic gradient descent that has recently seen broader adoption for deep learning applications in computer vision and natural language processing.
In this post, you will get a gentle introduction to the Adam optimization algorithm for use in deep learning.
After reading this post, you will know:
- What the Adam algorithm is and some benefits of using the method to optimize your models.
- How the Adam algorithm works and how it is different from the related methods of AdaGrad and RMSProp.
- How the Adam algorithm can be configured and commonly used configuration parameters.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
What is the Adam optimization algorithm?
Adam is an optimization algorithm that can be used instead of the classical stochastic gradient descent procedure to update network weights iterative based in training data.
Adam was presented by Diederik Kingma from OpenAI and Jimmy
To finish reading, please visit source site