Text Summarization using NLP to fetch BBC News Article and summarize its text and also it includes custom article Summarization
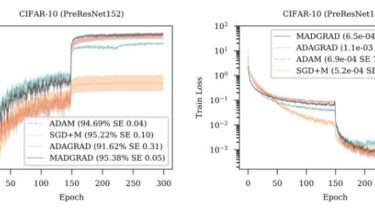
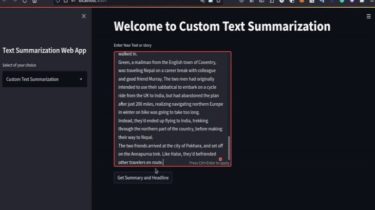
Text Summarization using NLP to fetch BBC News Article and summarize its text and also it includes custom article Summarization Features Of Data Analysis Web App Get your custom Text Summarized. we automatically Summarize text of BCC News so that you dont have to read whole article. Check out the live demo: https://text–summarization.herokuapp.com/ Vedio demo: Use this URL – Click Me – in case if you are faccing any problem with source code. Source Code: github link How to run […]
Read more