ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
News & Updates
(24/08/2021)
- Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model.
(15/08/2021)
- Release the basic framework for ROSITA, including the pretrained base ROSITA model, as well as the scripts to run the fine-tuning and evaluation on three downstream tasks (i.e., VQA, REC, ITR) over six datasets.
Introduction
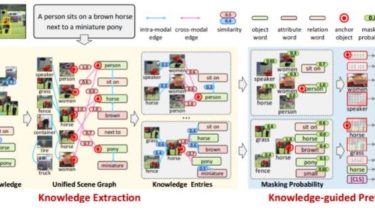
This repository contains source code necessary to reproduce the results presented in our ACM MM paper ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration, which encodes the cROSs- and InTrA-model prior knowledge in a in a unified scene graph to perform knowledge-guided vision-and-language pretraining. Compared with existing counterparts, ROSITA learns better fine-grained semantic alignments across different modalities, thus improving the capability